This article first appeared on WeChat public number: data view. The content of the article belongs to the author's personal opinion and does not represent the position of Hexun.com. Investors should act accordingly, at their own risk.
Cutting edge dry goods
Data view
Recently, at the 2017 Hangzhou·Yunqi Conference-Ali Big Data Sub-forum, Zhang Lei, senior technical expert of Alibaba's Data Technology and Products Department, delivered a speech on the theme of “Alibaba Global Data Constructionâ€, sharing Ali's precipitation in big data. Technical capabilities and application practices.
Alibaba Data Technology and Products Division Positions Alibaba Data Center: Focusing on global big data construction, the technology covers all links of the entire big data collection, processing, service and consumption, and provides internal and external services. The rich big data ecological components constitute Ali's core data capabilities. Through the big data ecological components, it can quickly improve the iterative ability of data applications, and everyone can become a big data expert.
In the process of global data construction, Alibaba OneData system was also constructed as a big data standardization specification, from method theory to landing practice; from the definition of indicators, data development, data service management to data specification definition, model specification definition, research and development process Standardization; each link has a corresponding tool to strictly guarantee, and to facilitate management, problem traceability.
See below for details + PPT
Click on the image to zoom to view the HD image
{ Part1 } Data in the Taiwan-Alibaba Data Technology and Product Division
In 2016, Alibaba Group proposed the concept of middle office. Alibaba Data Technology and Products Department carried the work of group data in the middle of Taiwan, and its core is to build global big data.
From the content point of view, we manage and operate the core data of Alibaba Group;
From a technical point of view, we cover every link on data links, from data collection and computational processing to data services and data applications, providing full-link, omni-channel data for businesses, users, and small and medium-sized businesses inside and outside Ali. service.
For example, the well-known double 11 shows that the cool data big screen is responsible for our department.
[Ali data in the middle of the panorama]
|
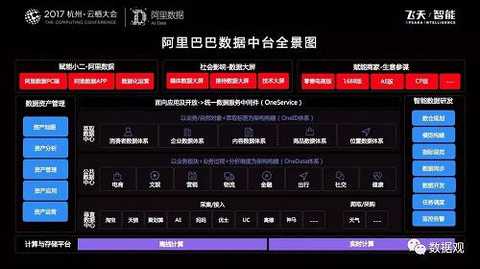
The above picture is a panoramic view of the Alibaba data center. From this figure, we can see that the actual data platform of the Ali data platform presents a “four horizontal and three vertical†structure. The bottom infrastructure comes from Alibaba Cloud. platform.
Let’s talk about four horizontals first.
The whole architecture diagram is viewed from the bottom up. The bottom part of the content is mainly from the perspective of data collection and access. According to the state access data (such as Taobao, Tmall, Box Horse, etc.), we extract the data to the computing platform. Then, through the OneData system, the "public data center" is built with the "business segment + analysis dimension" as the framework; and then based on the public data center in the upper layer according to business needs: consumer data system, enterprise data system, content data system, etc. After deep processing, the data can be used by its products and business. Finally, unified data services are provided through the unified data service middleware “OneServiceâ€.
Within Ali, there are dozens of data products on the Ali data platform. Every day, tens of thousands of internal employees use data products; our official unified data product platform “business staff†has accumulated more than 20 million merchants...
Next is the three verticals -
Behind the construction of such a large amount of data system in Alibaba, we must ensure a fast, efficient and high-quality data access through a large number of tools. This part is realized through the intelligent data development platform, and our theory and practice process is passed. A set of tool system and R&D process to ensure the landing, to ensure that each team, every BU, through a unified rules to build a data system; at the same time, when the data is more, the most direct problem is the cost, so we have also established a unified data Quality management platform.
{ Part2 } What is the global data?
Alibaba's current ecological construction includes the core e-commerce business, Taobao, Tmall, and cost-effective, as well as the Youku, Potato, UC browsers in the entertainment sector, and of course localized services such as word of mouth, hungry, etc. . Behind the format are ants, rookies, Ali mothers, Alibaba Cloud, and so on.
|

This series of ecological data is centrally stored and managed and constitutes the scope of our global data coverage.
On the one hand, each of the above-mentioned formats is the source of global data; on the other hand, based on these high-quality data, it is parsed and processed, and then fed back to the business. What we want to achieve is: use global data to drive the business and make the data more valuable.
Take Hand Tao as an example, the screen of the mobile phone is very small. How do we show the users in a limited space to see what they really want to see? Behind the application of “Thousands of People†is actually based on the algorithm application scenario of big data. There are also sesame credits, intelligent logistics of rookie, precision marketing of Ali Mama, etc., all of which are driven by big data and constitute a closed loop of business and data connectivity.
{ Part3 } The original intention of the construction of Ali's global data
Why do we have to do global data?
First, reduce costs -
Everyone knows that the capital investment in big data construction is actually very huge. For example, infrastructure investment, equipment room, rack, server, network bandwidth, including software platform construction, development of operation and maintenance team, etc., will cost a lot of money and manpower. Take Youtu (short for Youku Tudou) as an example. After Youtu joined Alibaba Group last year, we started the data fusion project: Before this, Youtu had its own Hadoop cluster, and Alibaba’s data was much larger. The integration of the excellent soil data into the Ali platform can enable the superior soil to obtain more flexible resources, and also reuse the group's technical system in infrastructure operation and maintenance, human operation and maintenance, and platform operation and maintenance; based on the OneData big data construction system, Uniform data collection specifications, etc., reduce manpower and operation and maintenance costs. When the project was completed, we found that the cost of the current land construction data was less than 50%.
Second, technology empowerment -
Objectively speaking, the data capabilities of companies in Ali Eco are uneven, so in order to empower other eco-companies, we have the same big data capabilities as Ali Group through a short-term data system migration. The above-mentioned excellent soil integration project achieved technical empowerment through half a year.
Third, the data connection -
We know that the phenomenon of data silos not only exists in traditional industries, but also in the Internet industry. Therefore, only by connecting the data, it can exert greater value, eliminate data islands, and connect data. It is also one of the purposes of our global data construction.
Finally, empowering the business -
No matter how large our cluster is and how large the service volume is, we will eventually return to the business and reflect our value through the data performance of the business. After the data system is unified, the business can obtain more accurate and rapid decision analysis. In addition to data, it also provides opportunities for quick trial and error of business, which ultimately lowers the threshold for business innovation.
{ Part4 } How to build global data
In the entire global data access process, although the infrastructure construction is already very strong, in the actual process, we still face many difficulties and challenges. Still taking the excellent soil as an example, its big data room is in Qingdao. Most of the data clusters of the Ali Group are in Inner Mongolia and Zhangbei, and the data migration is not so simple as pulling a network cable. Both the system and the big data architecture require a customized solution;
In addition, unified data collection will be unified in the process of access, including the subsequent data verification, people who have done data should know the pain points; at the same time, the original data pair in the migration process The service of the business can't stop. This is what we call—the wheels are changed on the plane, and the core parts are updated, while maintaining high-speed flight.
Finally, the project cycle, based on the reality, big data construction generally requires a long period of time, can not be completed in a few weeks, because big data construction is not a one-time, but a systematic process.
From the perspective of infrastructure, Ali has developed through e-commerce, including the test of special scenarios in the past 11 years, from the data center to the network to the server, to the database middleware, computing platform, data platform, algorithm platform. There is a lot of precipitation.
Therefore, when building global data, the first step we need to do is to integrate the data of the eco company in the infrastructure phase.
|
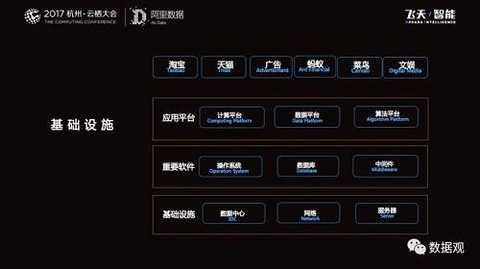
Our data components are divided as follows:
The bottom layer - data collection, this is the source of data; the middle - computing storage platform: real-time computing using self-developed Blink, offline using MaxCompute.
|
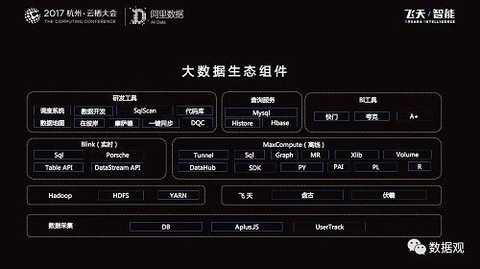
The above figure details our data components:
Based on the user's online behavior to do data collection (we have PC and wireless acquisition system) and then put it on the real-time, offline computing platform, in addition to their own computing power, these two computing platforms have many programmable based on SQL, Graph, etc. The top level is R&D tools, product services, and BI tools.
With such a strong foundational support, the application capability is also very strong: in the case of R&D tools, there are about 20,000 R&D engineers in Ali, and nearly 10,000 students work on the Ali data platform every day. !
Based on these rich big data components, most R&D students, professional or non-professional students can do some exploration and experiment based on big data above.
Here are a few of our systems in the construction of global data:
First look at the traffic system -
This is the biggest difference between the Internet industry and the traditional industry.
For example, if we can use Taobao as a traffic distribution center, users will send traffic to the seller and give it to the seller. Then, when doing traffic data collection, you may give different solutions.
Based on Alibaba's many years of e-commerce experience, we have also developed a unified set of flow acquisition specifications - super location model:
|
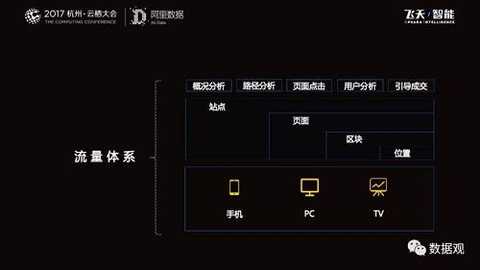
Take the Taobao page as an example:
The site is Taobao. There are pages, blocks, and locations below. These can be buried according to the actual needs of the business, and intuitively obtain data from any location on the page, such as page profile analysis, path analysis, jump analysis, page click, User analysis and more. The business side only needs to bury the point according to the specification, and we can quickly provide the basic traffic analysis capability. Based on this, the corresponding data product can solve the data problem of 80% of the traffic.
Second, look at computing componentization -
As we all know, the basic content of the Internet is actually able to solidify the specific needs, the intermediate process can be solved through engineering capabilities, and then quickly configure these things, without the need to do code development calculations for each requirement - this is the calculation Componentized.
The first advantage of this is that the configuration is simple and the reusability is high. At the same time, after paying attention to the unified specification, we can achieve one-click access by accessing uc and accessing high-tech services in the future.
|
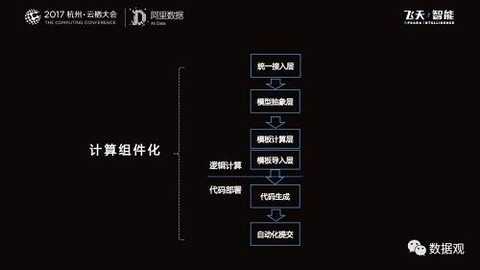
OneData system, the core system of global data construction -
At present, from the perspective of the entire big data construction process, it is divided into data access, specification definition, computational processing, data verification, and data stability. These parts are combined to form the overall data development process.
The OneData system tool is a guarantee of global construction - we know that storage and computing may not be the bottleneck. With the development of distributed technology, with Hadoop as a typical example, cheap PC servers can build superb computing power, so storage and computing will become cheaper and cheaper in the future, but the relatively expensive is the engineer's time cost. .
|
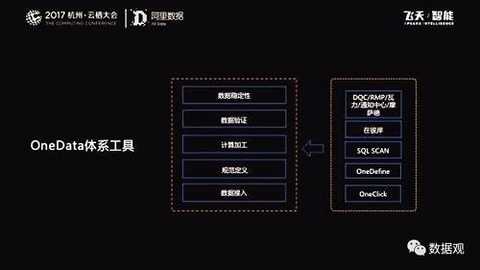
Therefore, instrumentalization is a key part of solving R&D efficiency. We put a lot of mechanical, human flesh, and non-productive work through tools. For example, from the access of data, we have OneClick to ensure efficient access. According to Alibaba's perfect metadata, we have the ability to put business based db. Data is pulled to the computing platform with one click, and this process requires little human involvement.
At the same time, the OneDefine tool ensures that the data construction process is standardized, such as model stratification, table naming conventions, and field naming conventions.
Look at the calculation process again -
The group of Ali data applications is uneven in terms of capabilities. There are professional data development, algorithmic engineers, analysts, and possibly business operations. Many people may simply run their own SQL and run the data themselves: Under the SQL quality can not be guaranteed, if the amount of data query is very large, thousands of machines in the background may be turned up. In order to avoid similar situations, we will do code verification during the submission of tasks, for performance problems, specification problems The code quality problem will give the necessary prompts. For example, the sql code does not have code compatibility for the divisor of 0. For example, we do not set the data life cycle in our ddl statement. For example, the query in sql does not have the condition limit for partitioning, or even Your sql code has been calculated by others, you can reuse the results without recalculating these problems, we will give accurate to the prompt.
In the data development process, code writing may only account for 20% of the workload, so what do you do most of the time? Is the data verification, before the code is modified and after the code is modified, how much is the data in the end, where is the difference? In the past, if there was no tool, only a bunch of scripts could be written, and then verification, the efficiency was extremely low, and it was extremely error-prone. Now with the "on the other side" tool, we can use the simple tick to select the difference between the front and the back. ? Then quickly report the test to ensure that the data quality of the entire development process is guaranteed.
Finally, after the task is online, a lot of time is in operation and maintenance, monitoring data quality, monitoring output time, etc., we will have relevant tools to support these daily work, so the OneData system tool is global data construction. Important Guarantee.
With tools and specifications, we need to work with the R&D process. We can ensure that the specifications are truly implemented on every developer. So we can understand the R&D process like this: A R&D class is doing data needs. You must first complete the specification definition to continue code development.
|
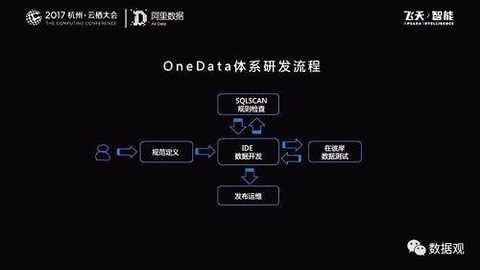
There are two checks in code development:
The first is SQLscan: this will check code specification, code quality, possible performance issues, and avoid these problems;
The other is the “on the other side†data test: after the important data has been changed, it will be required to do the regression test process. It is easy and simple to check and you can quickly give the test. If the task needs to be run in a production environment, these two links must be completed before they can be submitted. The above process is the entire development process based on the OneData system.
At present, Alibaba's total data has exceeded the EB level, and the total number of tables has exceeded one million. Under such a large amount, how can we achieve efficient and flexible big-data construction without losing the norm, we have really explored for a long time.
With the continuous expansion of Ali's business, the requirements for big data capabilities will become higher and higher. Technically, how to break through the traditional digital warehouse etl architecture? We have begun to explore from the separation of computing and storage of infrastructure, offline online distribution, etc. We believe that in the near future, we will redefine the traditional number of warehouses etl.
Chainsaw Boot,Best Chainsaw Boots,Chainsaw Safety Boots,Chainsaw Protective Boots
zhejiang leima shoes ind.co.,ltd , https://www.safetyshoeschina.com